第43回目は「Semantic Image Segmentation」について、詳しく説明していきます。
今回は、Semantic Image Segmentationの内「Conditional Random Field (CRF)」を用いた手法を紹介します。
Conditional Random Field (CRF)とは
まずはCRFとは何かを見ていきます。CRFは系列ラベリングという問題を解く手法です。機械学習の中では識別モデルに分類され、構造学習を行えるものがCRFです。
■系列ラベリングとは
文章のような文字の系列データに、主語、述語、目的語などのラベルを付与する問題のことです。入力が画像データの場合は、画素が2次元に配置された系列データとみなし、どの領域が人で、どの領域が道路で、といったラベルを付与することになります。
■識別モデルとは
第22回で紹介しているSVMやAdaBoost、Random Forestなどは、機械学習の中の識別関数に分類され、入力データが「人」なのか「人以外」なのかといったようにデータを分類するために用います。一方、CRFは機械学習の中の識別モデルに分類されます。SVMなどの識別関数は「人」「人以外」のようにデータを分類するためのものですが、識別モデルは、入力データがどのクラス(ラベル、カテゴリ)に属するかを確率値として求めることができます。
■構造学習とは
構造学習とは、データを1つずつ「人」なのか「人以外」なのかを判別するのではなく、その前後、上下左右、または入力データ全体の関係性を考慮して、全体として最適なラベルを付与する手法です。入力データが画像の場合は、人は道路の上に立っていて、人の上の領域は空である可能性が高いという構造関係を考慮して、人、道路、空を同時にラベリングすることになります。
つまり、画素が2次元に配置された入力データ系列に対して、人、道路、空の位置関係を考慮し、全体が最適となるようにどの領域が人で、どの領域が道路かを、確率的にラベリングできるのがCRFなのです。
Conditional Random Fieldを用いたSemantic Image Segmentation
CRFを用いたSemantic Image Segmentationの手法として、ShottonらがTextonBoostという手法[1]を提案しています。
この手法ではまず始めに、図1のように入力データに対して17種類のフィルタを畳み込み、注目画素近傍のテクスチャ情報を求めます。これを全画素に適用し、フィルタのレスポンスに対してK-meansクラスタリングを適用して、各画素に最近傍のクラスタの中央値を割り当てることでTexton mapを生成します。
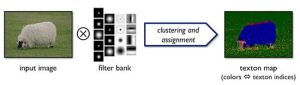
図1 画素近傍のテクスチャ(Texton)の計算
そして図2に示すように各注目画素iの近傍に様々なサイズ、位置の矩形領域を設定し、その矩形内に含まれるTextonをカウントし、そのレスポンスを特徴量として求めます。その特徴量をもとに、Boostingアルゴリズムにより各画素がどのラベル(物体)に属するかを学習し、識別します。この処理で、Semantic Image Segmentationの結果を得ることはできますが、精度が低く、特に物体の境界で多くのエラーが生じてしまいます。
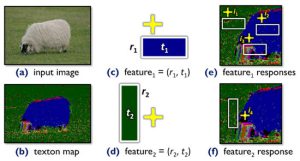
図2 Texton mapからの特徴量抽出
そこで最後に、得られたラベリング結果を、CRFを用いて画像全体で最適化します。具体的には、数式1の条件付き確率を最大化するように画像全体のラベル系列を求めます。
1つ目のshape-textureは、前述のTexton mapとBoostingアルゴリズムを用いたラベルの推定結果、colorは各ラベルの色情報に関する条件、locationは各ラベルの画像の位置に関する条件、edgeは色が変化するエッジにおいて隣接画素が取り得るラベルの組み合わせに関する条件です。
例えば空であれば、薄っすらとしたグラデーションの色・テクスチャを持ち、白から青の色情報で、画像の上部に存在する可能性が高く、かつ木や建物と隣接する可能性が高い、という4つの条件から総合的に空か否かを判断できます。
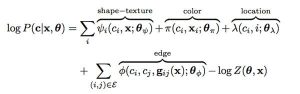
この手法により得られたSemantic Image Segmentationの結果は図3のとおりです。CRF無しのBoostingアルゴリズムのみによるラベリング結果では、足や尻尾の細かい領域の精度が低いことがわかります。それが、colorの条件を含むCRFを用いることにより輪郭が明瞭になるとともに、足や尻尾の細かい領域も正しくラベルを付与することができています。
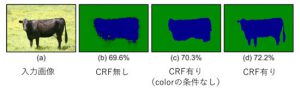
図3 TextonBoostによるSemantic Image Segmentation結果
今回はCRFを用いたTextonBoostという手法を紹介しました。近年、Semantic Image Segmentationの分野でもディープラーニング(Deep Learning:深層学習)が大きな成果を上げています。しかし、十分な学習データ数を集められない場合などには、ディープラーニング以外の少し古い手法の方が良い結果が得られることもあるので、今回紹介した手法も知っておくと良いでしょう。
次回は、今回に引き続き「Semantic Image Segmentation」に関する「Convolutional Neural Networks (CNN)」をベースとした手法をいくつか紹介します!
参考文献
[1] Shotton J., Winn J., Rother C., Criminisi A.: Textonboost for image understanding: MuIti-class object recognition and segmentation by jointly modeling appearance, shape and context. International Journal of Computer Vision, Vol. 81, No. 1, pp. 2-23, 2009.