第22回目の今回は、顔検出、人検出などで用いる識別器についてもう少し詳しく解説したいと思います。
ニューラルネットワーク(Neural Network)、サポートベクターマシーン(SVM:Support Vector Machine)、ランダムフォレスト(Random Forest、またはRandomized Trees)、AdaBoostなどがあります。
今回は、その内のSVM、Random Forest、AdaBoostについてご紹介します。
ニューラルネットワークは、大流行中のディープラーニング(Deep Learning:深層学習)で用いられています。Deep Learningについては、次回解説します。
SVM (Support Vector Machine)
2クラス識別では、特徴量ベクトルxから推定値yを求める問題として解くことになります。SVM(正確には線形SVM)では、y=wTx+bとなります。識別境界のパラメータベクトルwTとバイアスbを学習時に求め、学習済みのwTとbを用いて未知のデータの推定値yを求めます。そして、推定値yが閾値以上であれば顔、閾値未満であれば顔以外といった具合に判定します。
ここで、パラメータベクトルwTとバイアスbをどのように求めるかが問題になりますが、SVMではマージン最大化という考え方を用います。具体的には図1のように、学習データの中で他クラスに最も近いサンプル(サポートベクトル)を基準とし、サポートベクトルと識別境界の距離(マージン)が最大となるようにwTとbを求めます。
今回は、最もシンプルな線形識別について説明しましたが、SVMはカーネルトリックと呼ばれるテクニックにより非線形な識別器を構成することもできます。
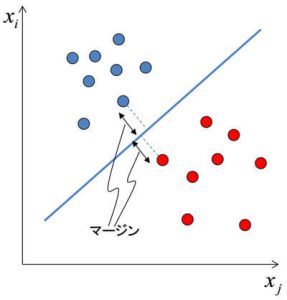
図1 SVMによる2クラス識別
AdaBoost
AdaBoostは、N個の弱識別器(h1(x), h2(x), h3(x), …, hN(x))の重み付き多数決により、最終的な推定結果を得る手法です(図2)。各弱識別器は、例えば、特徴量ベクトルX=(x1, x2, …, xN)の特徴量x5のみを用いて、x5>αを満たすか否かを判定する関数です。
AdaBoostは、各弱識別器が苦手なデータを補完し合い、全体として高精度な識別器を構成する仕組みです。「三人寄れば文殊の知恵」の機械学習版ですね。
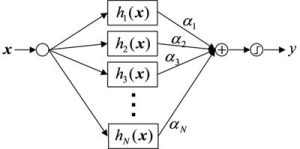
図2 AdaBoostによる2クラス識別
Random Forest
Random Forestは、複数の決定木を用いて、識別する手法です。Random Forestの処理は、「学習データから、ランダムサンプリングによりB組のサブサンプルを生成し、そのサブサンプルを用いてB個の決定木を生成する」、「特徴量のうちm個をランダムに選択し、選択された特徴量のうち、学習データを最も良く分類できる特徴量とその閾値を求める」というように、学習時にランダムな処理が用いられるためにRandom Forestと呼ばれています。
Random Forestは、図3の例に示すように、x5>αを満たすかまず判定し、次にx3>βを、といった具合に各特徴量の値と閾値をもとに決定木を辿っていき、各決定木ごとに顔か顔以外かを判定します。そして、各決定木の推定結果の多数決により最終的な結果を得ます。
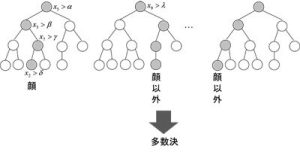
図3 Random Forestによる2クラス識別
SVM、AdaBoost、Random Forestのどれを使えば良いのかという疑問が生じるかもしれませんが、現時点ではこれを使えば良いというデファクトスタンダードはありません。自分が解こうとしている問題には、どの識別器が適していそうかを考え、識別器のパラメータも変えながら複数の識別器を試してみるのが良いと思います。
どの識別器を用いるかよりも、どのような特徴量を用いるかの方がより重要です。特徴量空間でそれぞれのクラスが分離できていないと、どの識別器を用いても精度良く識別することはできません。解きたい問題に合った特徴量を選択、設計する必要があります。
次回は、コンピュータビジョン分野でよく用いられるディープラーニングの手法「CNN:Convolutional Neural Network」について説明します!