第54回目は、YOLOと比較されることの多いSSD[1]について説明します。
SSDは、Single Shot MultiBox Detectorの略で、前回紹介したYOLOと同様に、画像を入力するとsliding windowsでwindowを少しずつスライドさせながら繰り返し処理するようなことはせず、1回で入力画像全域から複数の物体を検出できます。精度はFaster R-CNNと同等ですが、大幅な処理速度向上(59FPS)を達成しています。YOLOの最初のバージョンよりも高性能かつ高速な手法です。
SSDの概要
SSDの処理の概要は図1の通りです。SSDの教師データはYOLOと同じで、入力画像中に写っている検出したい物体のバウンディングボックスです。図1の例では犬と猫の外接矩形が教師データとして与えられています。
SSDでは、入力画像からまず何段かのスケールのfeature mapを求めます(図1(b)、(c))。そして、feature mapの各位置において、事前に定義しておいた異なる縦横比、サイズの矩形(図1の例では4個)を各feature mapに適用し、矩形内の特徴を畳み込みます。図1の例では、(b)と(c)の8×8と4×4の異なるスケールのfeature mapに対して、複数の矩形で特徴量を畳み込んでいます。そして各矩形ごとに、物体が存在する領域のバウンディングボックスの位置とサイズ(loc:⊿(cx, cy, w, h))、およびそのバウンディングボックス内の物体がどのカテゴリに属するかを表す確信度(conf:(c1,c2,…cp))を求めます。
学習時は、点線の青い矩形と、教師データである実線の青い矩形の位置、大きさが一致するように、かつ物体カテゴリが猫となるようにディープラーニングの重みが更新されることになります。同様に点線の赤い矩形と、実線の赤い矩形の位置、大きさが一致し、犬と推定できるように学習します。
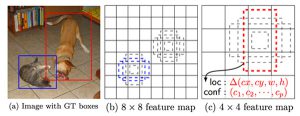
図1 SSDの概要
SSDのネットワーク
SSDは、図2を見れば分かるように、後段に向かうほど特徴マップをスケールダウンしていきます。事前に規定した矩形は、スケールダウンした特徴マップ上では相対的に大きくなるため、より大きな物体を検出できます。図1では前段の特徴マップ(図1(b))で猫を検出することができ、後段のスケールダウンした特徴マップ(図1(c))で犬を検出することができます。
SSDは、画像を入力すると、1つのネットワークで物体のバウンディングボックスの座標とサイズ、物体のカテゴリを出力することができます。つまりEnd-to-Endを実現できており、入力画像と教師データを準備すれば、複数の物体を検出しカテゴリを推定するための重みを一気に学習させることができます。

図2 SSDのネットワーク
「YOLOの最初のバージョンよりも高性能かつ高速な手法です」と冒頭に書きましたが、YOLOは複数のバージョンがリリースされており、大幅に性能が改善されています。最新の情報を調べて、最善のものを選択するようにしてください。
次回は、2017年に開催されたコンピュータビジョン分野のトップカンファレンス「ICCV2017」でBest Paper Awardを受賞した「Mask R-CNN」を紹介します!
参考文献
[1] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu,Alexander C. Berg, “SSD: Single shot multibox detector. ” in ECCV2016.