第52回目は、「Faster R-CNN」[1]の概要について解説します。
前回の「Fast R-CNN」と似ていますが、こちらの方がより新しく、高性能な手法です。まずは全体像から説明していきたいと思います。
Faster R-CNNの概要
Fast R-CNNは、一般物体検出の大部分をディープラーニングで実現しましたが、物体候補(Region Proposals)を検出するアルゴリズムは依然として、第49回でも触れたディープラーニング以前の手法であるSelective Searchを用いていました。つまり、画像の入力から物体候補抽出までと、物体候補から物体の識別までが分断されてしまっており、画像の入力から物体検出までを1つのモデルで一気に学習・推定することができるEnd-to-Endには至っていませんでした。
そこで、Faster R-CNNではSelective Searchの代わりとなる「Region Proposal Network(RPN)」という物体候補領域を推定するためのネットワークを導入することで、画像の入力から物体の検出までをEnd-to-Endで学習・推定できるモデルを提案しました(図1)。
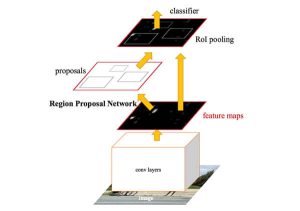
図1 Faster R-CNNの概要
Region Proposal Networkとは
Faster R-CNNとFast R-CNNの大きな違いは、Region Proposal Network(RPN)です。RPNは、入力画像中から物体候補領域(物体が存在し得る画像領域の候補)を抽出するためのネットワークです。
Fast R-CNN以前の手法では、物体領域抽出にSelective Searchと呼ばれる、ディープラーニング以前の手法を使っていました。そのため、抽出性能が低く候補が無数に抽出されてしまい、物体候補領域の抽出とその後の識別処理の計算コストが膨大となってしまっていました。
Faster R-CNNでは、物体候補領域の抽出をディープラーニングのモデルに取り込み、End-to-Endで学習・推定することで高性能な物体候補領域の抽出を実現し、その結果従来よりも高速かつ高性能な一般物体検出を実現しています。
RPNは、物体候補を出力するための2つの機能を持っています。1つ目は、図2中の赤枠内の画像が物体かどうかを表すスコアを計算する機能(図2中のcls layer)です。2つ目は、赤枠の外接矩形のスケールや位置を回帰により微調整する機能(図2中のreg layer)です。赤枠は、あらかじめ定義されたk個の外接矩形(Anchor)を用いて決定されます。このAnchor boxにさまざまな形、サイズを用意しておくことで、多種多様な物体を検出できるようになります。
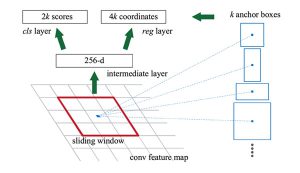
図2 Region Proposal Network(RPN)の概要
物体候補領域の抽出後はFast R-CNNと同様に、Feature maps上の物体候補領域内から、ROI poolingによって物体サイズによらず同一サイズの特徴量ベクトルを生成し、物体識別用ネットワークに入力することで最終的な物体検出結果を得る仕組みとなっています(図1)。
次回は、処理速度の早いYOLOについて紹介します!
参考文献
[1] Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks.” in NIPS2015.