第35回ではOpenCVに組み込まれている5つのトラッキング手法のうち、Boosting、MIL、Median Flowを紹介しました。
第36回目の今回は、残りの2つの手法のうちTLDの概要について紹介します。
TLD (Tracking Learning Detection)
TLD[1]は、追跡対象の物体の画像を随時学習しながら追跡を行う手法です。学習、検出、追跡の3つのステップを毎フレーム行います(図1)。
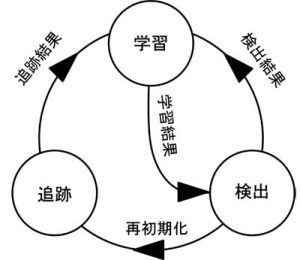
図1 TLDの処理の流れ
■ステップ1:
最新の学習データを用いて2クラス識別器の学習を随時行います。追跡を開始する初期フレームでは、追跡対象のBounding Boxを手動で与え、そのBounding Box内からPositiveサンプルを、その周辺の領域からNegativeサンプルを生成します。
■ステップ2:
次に最新の学習結果を用いて、画像全体を探索し追跡対象の物体を検出します。このとき、識別器は追跡対象が1つであるにも関わらず複数検出してしまったり、1つも検出できなかったりすることがあります。TLDではPL-Learningというアルゴリズムを用いて、学習データのPositiveサンプル、Negativeサンプルを更新します(図2)。
具体的には、P-expertと呼ばれる処理で、時系列の追跡情報(軌跡)をもとに検出結果が正しいか否かを判定します。もし追跡処理で得られた現在位置の画像領域が、追跡中の物体ではないと判定されてしまっていた場合は、その画像領域をPositiveサンプルとして追加します。これにより検出漏れを抑制していくことができます。
N-expertと呼ばれる処理では、空間方向の制約(追跡結果から得られる現在位置と追跡対象物は画像中に1つしか存在し得ないという制約)をもとに、画像中のPositiveとして判定された検出結果が正しいか否かを判定します。まず、追跡結果から得られる現在位置を用い、最も確からしい検出結果を1つ選出します。そして、その最も確からしいと判定された検出結果とオーバーラップしていない検出結果をNegativeサンプルとして追加します。つまり、追跡対象物ではないにも関わらずPositiveとして誤検出してしまった画像領域をNegativeサンプルに追加することにより、誤検出(過剰な検出)を減らすことができます。

図2 P-N Learningの概要
■ステップ3:
追跡処理にはMedian Flowを用います。追跡対象のBounding Boxをグリッド状に分割し、各グリッド内の点の動き(Flow)を求めます。そして、トラッキングエラーが大きいFlowを除去し、残ったFlowの中央値を用いてBounding Boxの座標を更新します。このとき各グリッドのFlowのばらつきが閾値以上の場合、物体が完全に隠れてしまった、あるいは画像の視野外に出てしまったと判定します。
動画1 TLDによるトラッキング結果
TLDによるトラッキング結果は動画1のとおりです。P-N Learningにより、追跡処理を繰り返せば繰り返すほど識別器の精度を向上させることができます。また追跡処理と検出処理が独立しているため、物体が隠れた場合や物体が画像の視野外に出てしまった場合、追跡処理が失敗した場合にもリカバリーすることができます。
実際に使ってみた印象としては、物体の見え方の変化が小さい場合は精度良く追跡することができますが、回転や変形により見え方の変化が大きい場合は苦手なようです。
次回は、OpenCVに実装されているトラッキング手法のうち最後の1つであるKCFを紹介します!
参考文献
[1] Kalal, Z., Mikolajczyk, K., Matas, J.: Tracking-learning-detection. TPAMI 34(7), 1409-1422 (2012)