第31回目となる今回は、頭部に装着したGoProを用いてアメリカのディズニーランドで長時間撮影した映像から、会話しているシーンを抽出し、会話の種別(1対1か1対多かなど)を推定する手法を紹介します(参考文献: Fathi, Hodgins, and Rehg, “Social Interaction: A First-Person Perspective”, CVPR’12)。
一人称視点映像のメリット・デメリット
まず一人称視点映像のメリットとデメリットを整理します。
メリットには下記のようなものがあります。
・カメラ装着者の見ているシーンを常時撮像できる。
・カメラ装着者の頭部の動きの計測が容易である。
・インタラクション対象(人や物)を近距離かつ正面から撮像できる。
一方、デメリットは次のとおりです。
・カメラ装着者の動きにより、映像全体が動いてしまう。そのため、背景差分による移動物体の検出を用いることができない。
・映っている人物の動きと背景の動きの分離が難しい。
Social Interaction: A First-Person Perspective
Social Interaction: A First-Person Perspectiveの処理の概要は図1のとおりです。
まず入力画像(Input Frame)から、カメラ装着者の頭部の動き(First-person Head Movement)を求めます。同時に、入力画像から映像中に映っている人物の顔を検出します(Face Locations in 3D Space)。そしてそれらの人物がどこを見ているか(Patterns of Attention)、さらに誰が発話者で、誰が話を聞いているかを推定します(Roles of Individuals)。
図2は、Face Locations in 3D Space、Patterns of Attentionの結果の一例です。一人称視点映像では、カメラ装着者が会話している相手を近距離から撮影できます。この映像中から人物の顔を検出することで、誰がどっちを向いていて、誰が発話者かを推定できるわけです。
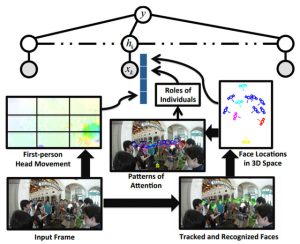
図1 処理の概要

図2 顔検出とAttentionの推定結果
そして、動画像の各フレームからこれらの観測値(First-person Head Movement、Patterns of Attentionなど)が得られるので、CRF(Conditional Random Field)を用いて会話の種別(1対1、議論、1対多、歩きながらの1対1、歩きながらの1対多)を推定します。
CRFは系列ラベリングを解くための手法で、構造学習を行うことができる識別モデルです。例えば文章が入力である場合、どの単語が名詞で、どの単語が動詞かをラベリングするための手法です。そして文章には文法というルールがあるので、単語を個々に名詞か動詞か識別するのではなく、全体として最適なラベリングを得ます。
下の動画は、グループでディズニーランドに行った際の一人称視点映像から、1対1で会話しているシーン、1対多で会話しているシーン、議論しているシーンなどを自動でラベリングした結果です。
会話種別の推定結果
このように一人称視点(First-person vision、Egocentric vision)では、カメラ装着者が見ているシーンを常時撮影することができ、かつインタラクション対象を近距離かつ正面から撮影できるため、日常生活の行動を記録、分析することができるのです。
次回は、複数の人物が存在するシーンで、どこのエリアが人々の注意を集め得るかを推定するSocial Saliency Predictionについて紹介します(参考文献: Park and Shi, “Social Saliency Prediction”, CVPR’15)。